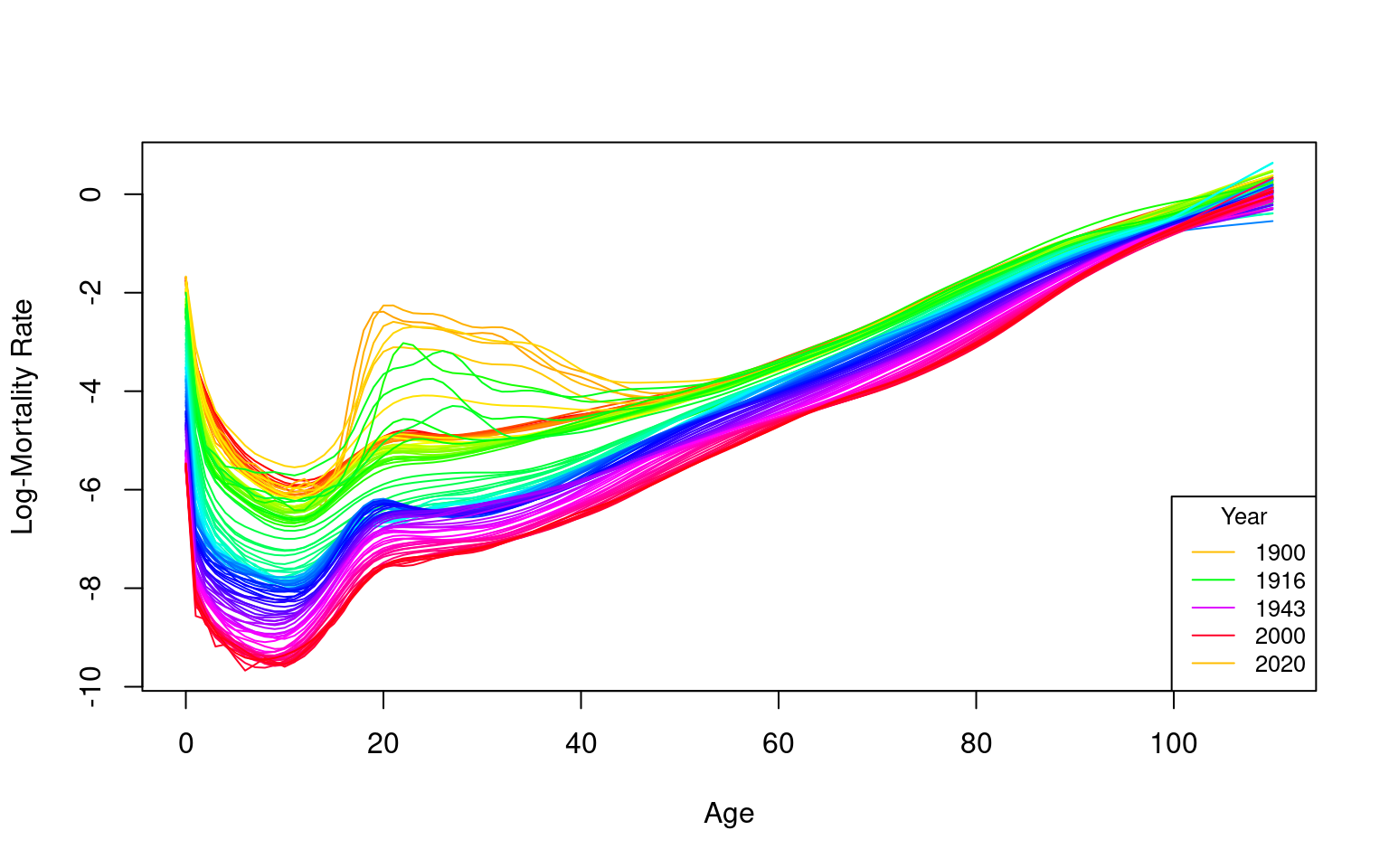
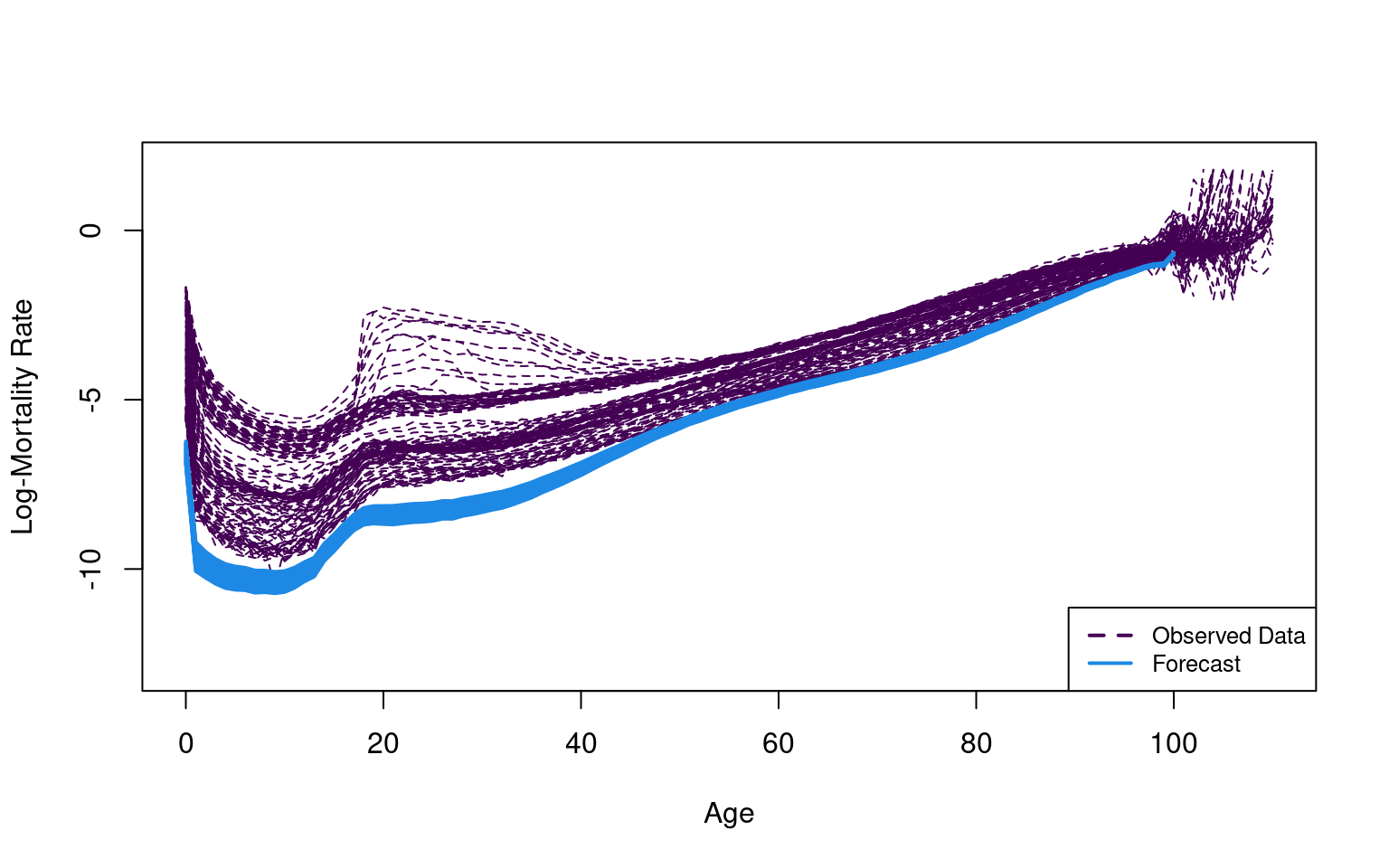
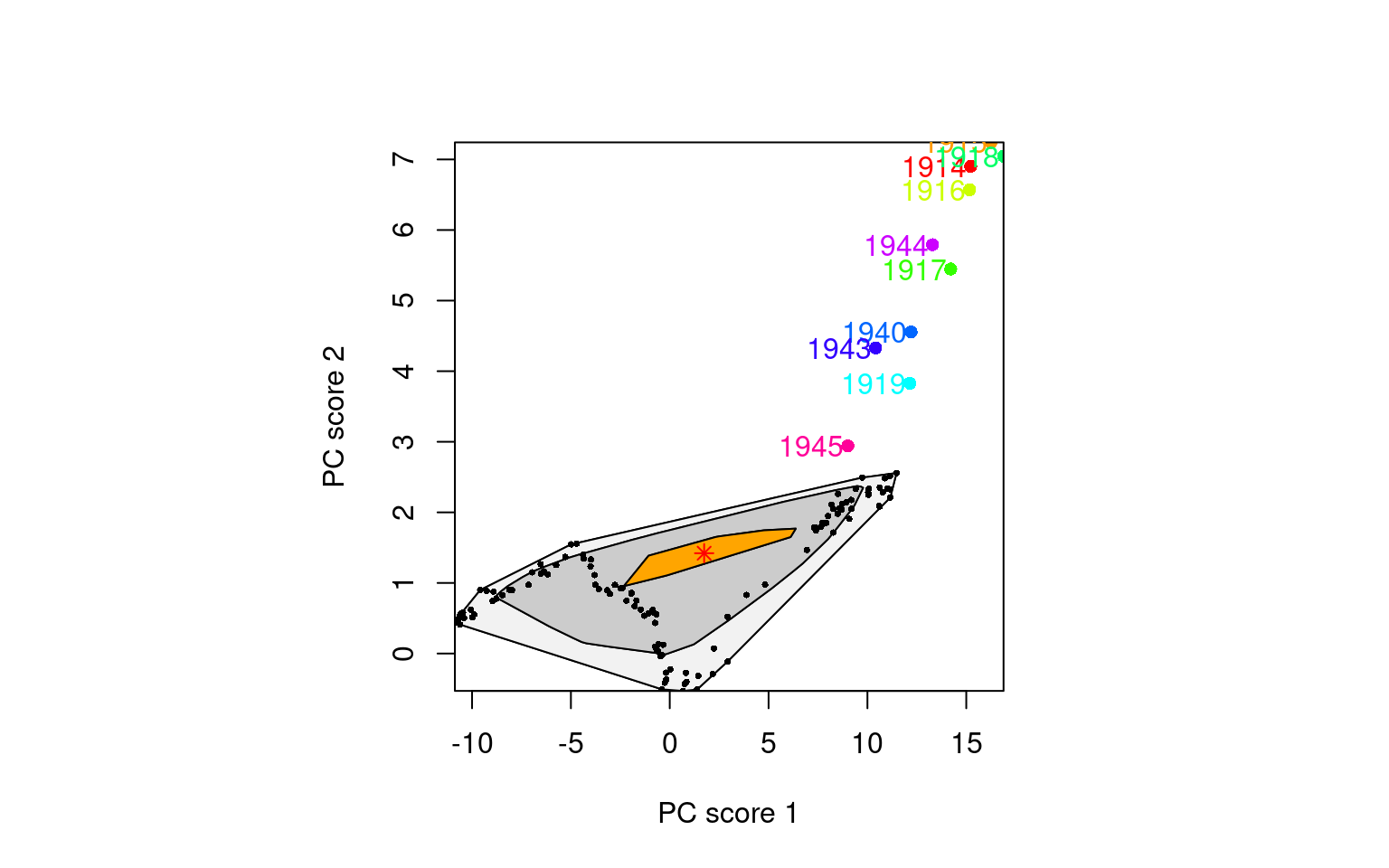
Outliers, or unusual data points, can seriously affect the performance of modeling and forecasting. The HUrob method is designed to eliminate their effect. This method utilizes the reflection-based principal component analysis (RAPCA) algorithm of Hubert et al. (2002) to obtain projection-pursuit estimates of principal components and their associated scores. The integrated squared error provides a measure of the accuracy of the principal component approximation for each year (Hyndman and Ullah (2007)). Outlying years result in a larger integrated squared error than the critical value obtained by assuming normality of (see Hyndman and Ullah (2007) for details). By assigning zero weight to outliers, the HUrob method can then be used to model and forecast mortality rates without the possible influence of outliers.
How the HUrob Method Works
The HUrob method uses an advanced technique called reflection-based principal component analysis (RAPCA). This technique helps to identify the main patterns in the data while filtering out those outliers that could lead to inaccurate predictions.
Here’s a simplified explanation:
-
Principal Components: Think of these as the main patterns in your data. The method tries to capture these patterns and ignore the noise or outliers.
-
Outliers: These are unusual data points that don’t fit the general pattern. If left unchecked, they can distort the model’s predictions.
By assigning zero weight to outliers, the HUrob method effectively ignores these problematic data points, making the model’s predictions more robust and trustworthy.
Using the functional data analysis paradigm of Ramsay and Silverman (2005), Hyndman and Ullah (2007) proposed a nonparametric method for modeling and forecasting log mortality rates. This approach extends the Lee-Carter (LC) method in four ways:
- The log mortality rates are smoothed prior to modeling.
- Functional principal components analysis (FPCA) is used.
- More than one principal component is used in forecasting.
- The forecasting models for the principal component scores are typically more complex than the RWD model.
The log mortality rates are smoothed using penalized regression splines. To emphasize that age, , is now considered a continuous variable, we write to represent mortality rates for age in year . We then define and write:
where denotes a smooth function of as before; allows the amount of noise to vary with in year , thus rectifying the assumption of homoskedastic error in the LC model; and is an independent and identically distributed standard normal random variable.
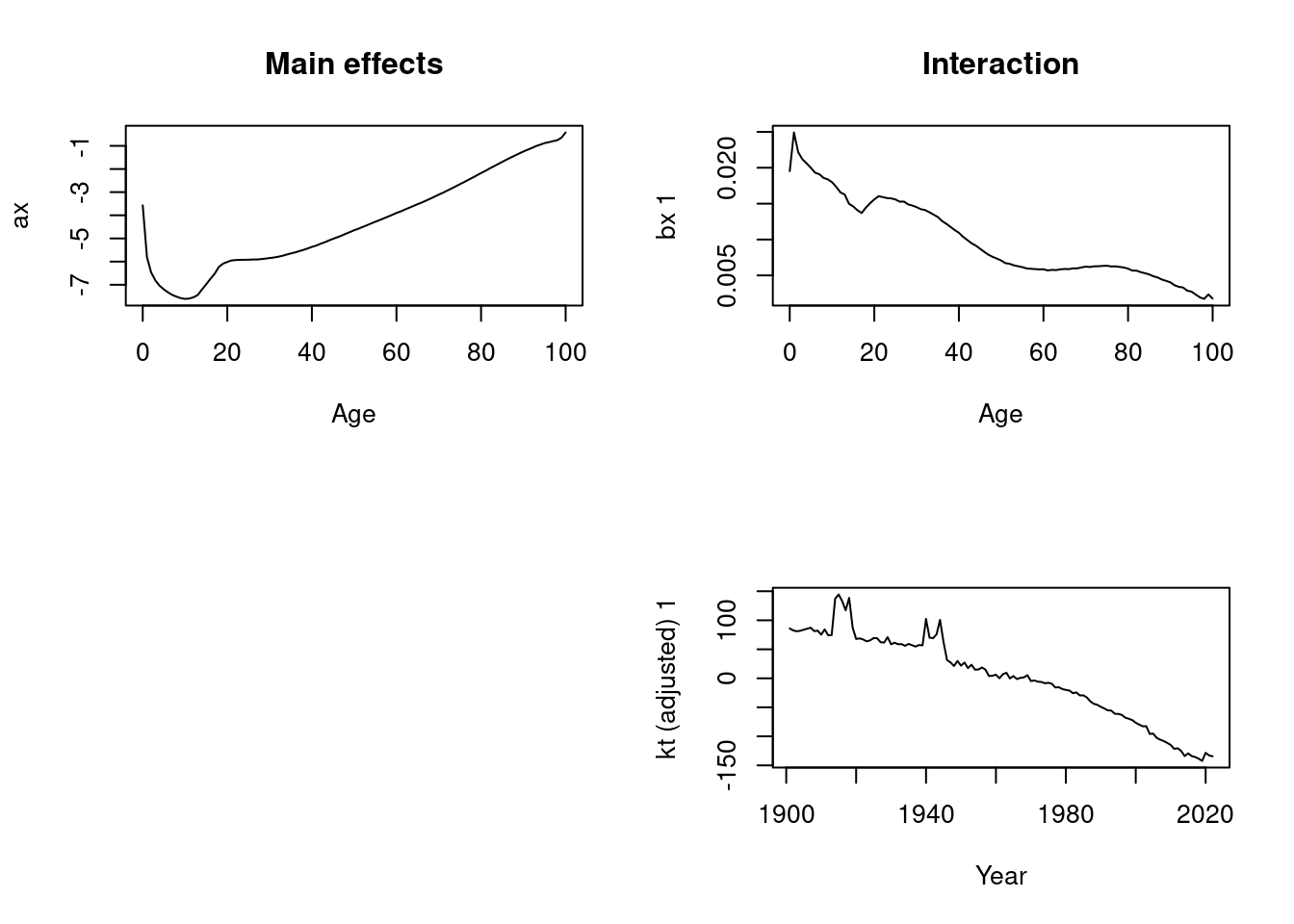
Given continuous age , functional principal components analysis (FPCA) is used in the decomposition. The set of age-specific mortality curves is decomposed into orthogonal functional principal components and their uncorrelated principal component scores. That is:
where is the mean function estimated by ; is a set of the first functional principal components; is a set of uncorrelated principal component scores; is the residual function with mean zero; and is the number of principal components used. Note that we use rather than to emphasize that is treated as a continuous variable.
Multiple principal components are used because the additional components capture non-random patterns that are not explained by the first principal component (Booth et al. (2002); Renshaw and Haberman (2003); Koissi et al. (2006)). Hyndman and Ullah (2007) found to be larger than the number of components actually required to produce white noise residuals, and this is the default value. The conditions for the existence and uniqueness of are discussed by Cardot, Ferraty & Sarda (2003).
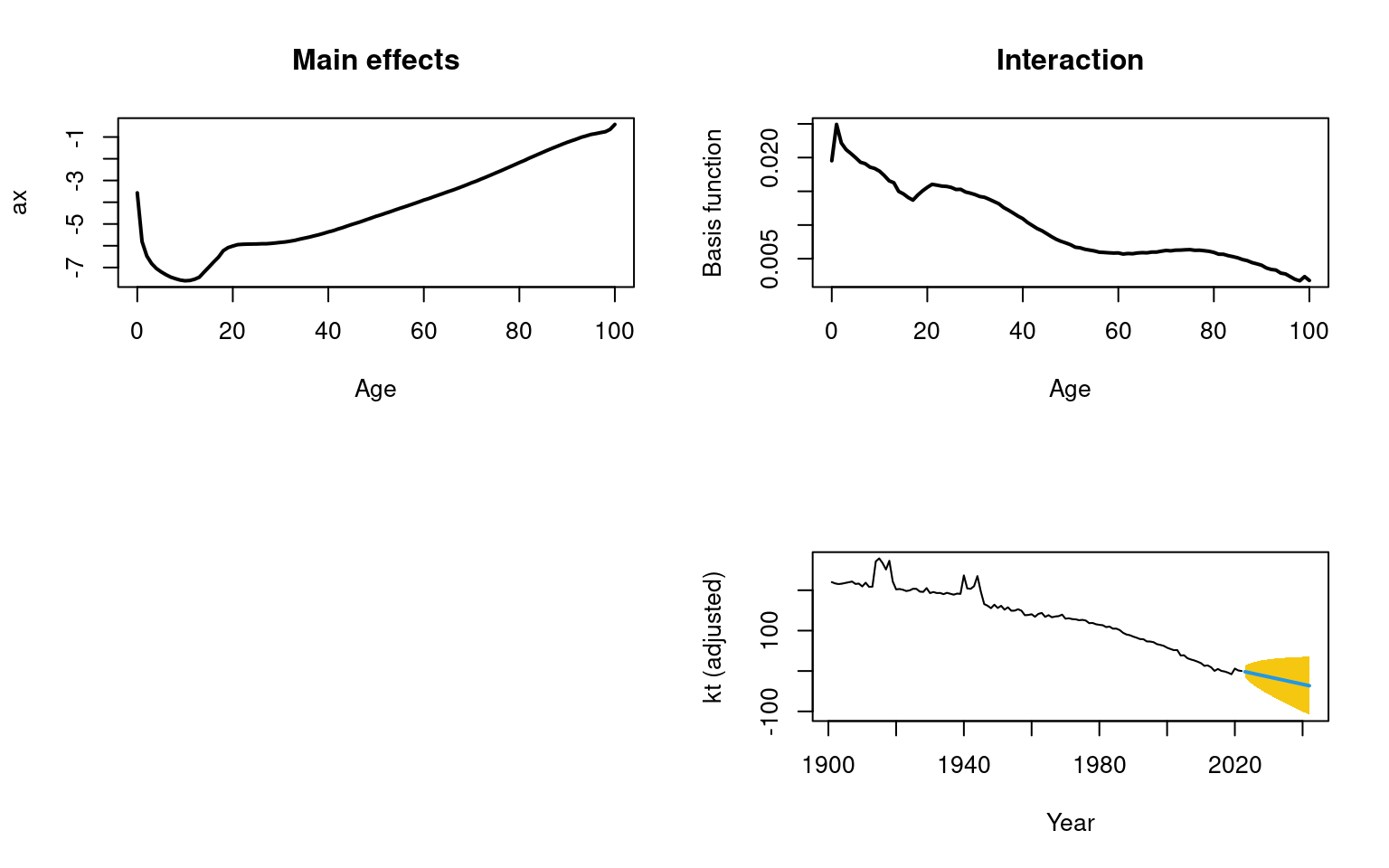
Although Lee and Carter (1992) did not rule out the possibility of a more complex time series model for the series, in practice, an RWD model has typically been employed in the LC method. For higher-order principal components, which are orthogonal by definition to the first component, other time series models arise for the principal component scores. For all components, the HUrob method selects the optimal time series model using standard model-selection procedures (e.g., AIC). By conditioning on the observed data and the set of functional principal components , the -step-ahead forecast of can be obtained by:
where denotes the -step-ahead forecast of using a univariate time series model, such as the optimal ARIMA model selected by the automatic algorithm of Hyndman et al. (2008), or an exponential smoothing state space model (Hyndman et al. (2008)).
Because of the orthogonality of all components, it is easy to derive the forecast variance as:
where is the variance of ; is the variance of (obtained from the time series model); is the variance of ; and is defined in Equation (2). This expression is used to construct prediction intervals for future mortality rates in R.
Key Enhancements Over Traditional Methods
The HUrob method improves upon traditional methods like the Lee-Carter (LC) model in several ways:
-
Smoothing: Log mortality rates are smoothed using techniques that stabilize the data, reducing the impact of random fluctuations.
-
Principal Components Analysis (PCA): Instead of relying on just one principal component, this method uses multiple components to capture more of the complexity in the data.
-
Advanced Time Series Models: For predicting future trends, the
HUrob method uses sophisticated models like ARIMA, which are more flexible and accurate than simpler models.
Putting It All Together
In simple terms, the HUrob method is a powerful tool for making more accurate predictions about future mortality rates. By carefully managing outliers and using advanced statistical techniques, this method helps actuaries and analysts make better-informed decisions, whether they are pricing life insurance products, setting aside reserves, or planning for the future.