In the realm of automobile insurance, Poisson regression is a reliable tool for understanding and predicting accident frequencies, repair costs, and claims trends.
By utilizing Poisson regression, insurers can anticipate forthcoming challenges, refine pricing strategies, and ensure resilience in a dynamic landscape of risk.
In this analysis, we will explore the relationship between the response variable ClaimNb and the explanatory variables DriverAge and Density. This modeling framework aligns with the principles outlined by Agresti (2013), a prominent figure in statistical methodology, who emphasizes the significance of considering multiple explanatory factors in regression analysis.
To model the frequency of insurance claims, we employ a Poisson regression approach. The response variable in our model, denoted as ClaimNb, represents the count of insurance claims and is assumed to follow a Poisson distribution:
where is the mean rate of claims. The Poisson regression model relates to a set of predictor variables through a logarithmic link function. This link function ensures that the predicted rate of claims is always positive, as required by the Poisson distribution. More precisely, we express the natural logarithm of as a linear combination of the predictors:
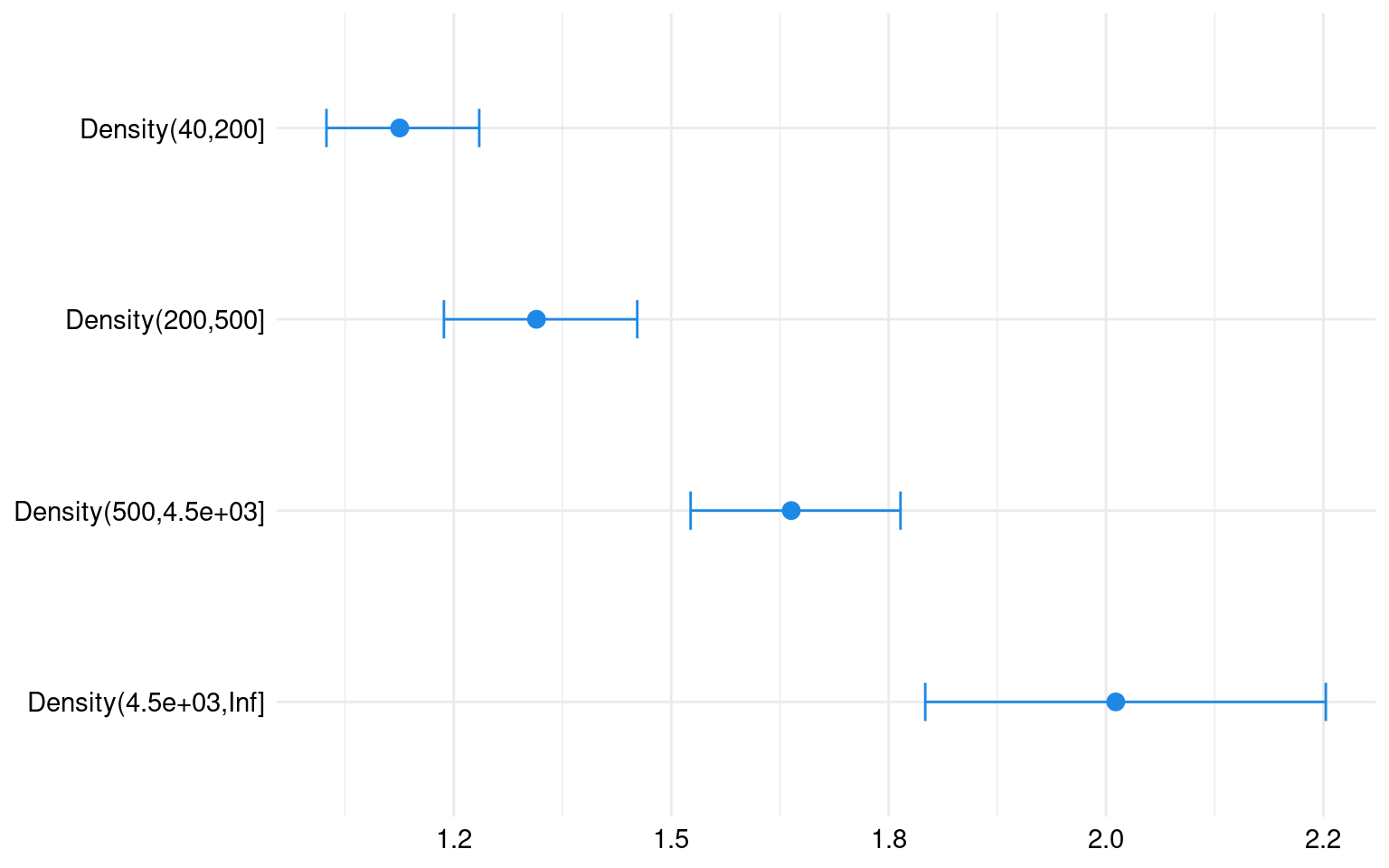
where DriverAge represents the age of the driver, Density indicates the population density of the city in which the driver resides, and , , and are the regression coefficients that need to be estimated.
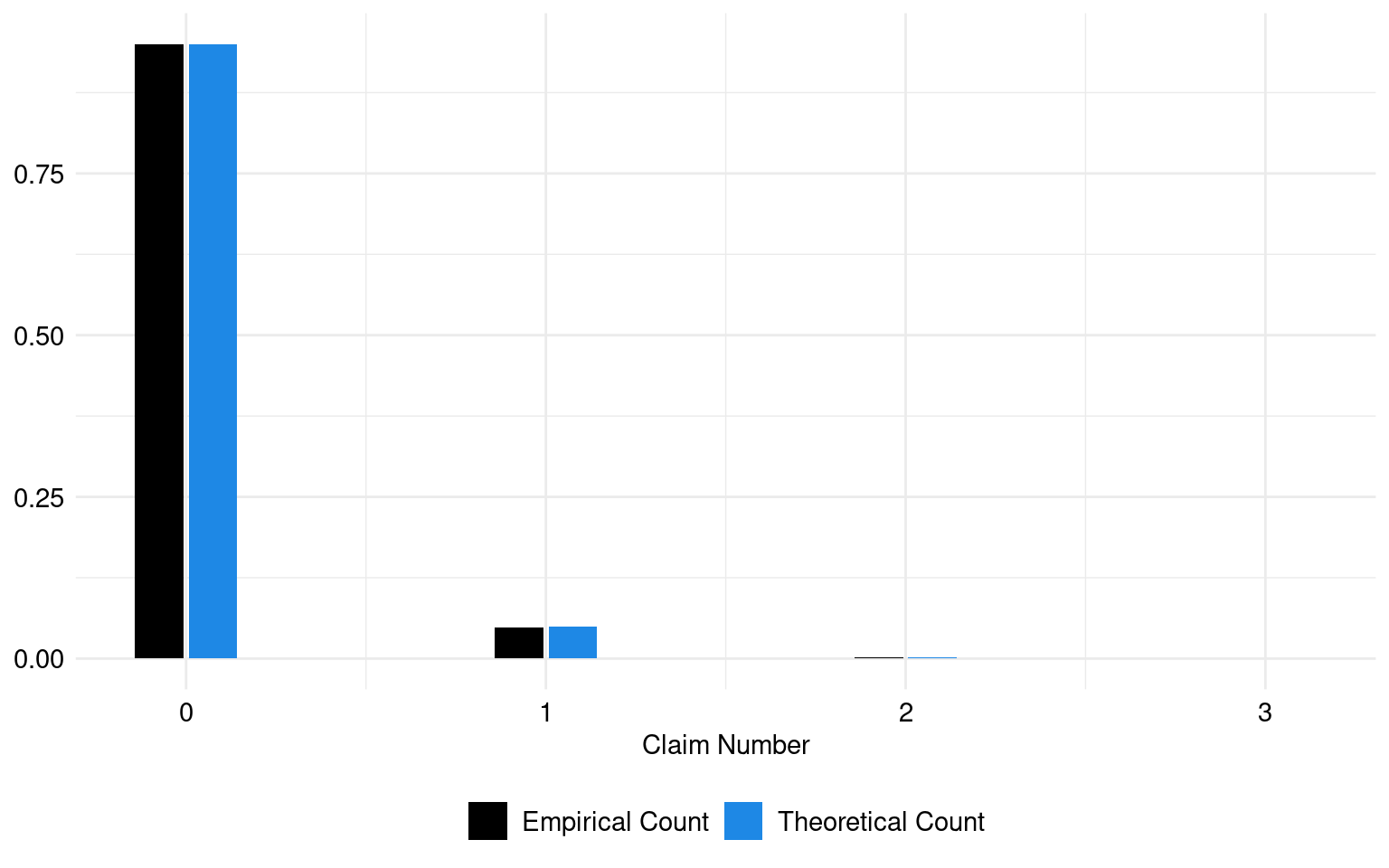
The estimated lambda parameter, which represents the mean of claims, is: 0.05.
The theoretical and empirical histograms associated with a Poisson distribution are shown in Figure 1.