Zero-inflated regression models offer distinct advantages over simple Poisson regression because they explicitly address zero inflation in the data. Zero-inflated models, such as Zero-inflated Poisson (ZIP) or Zero-inflated negative binomial (ZINB) regression, recognize that zeros can arise from two distinct processes: structural reasons (e.g., policyholders who never file claims) and random chance.
By incorporating these dual processes, zero-inflated regression models provide more accurate estimates and better predictions, particularly in scenarios where excess zeros are prevalent. This enhances the precision of risk assessments, improves the effectiveness of pricing strategies, and facilitates better decision-making for insurers operating in domains like automobile insurance. These models excel in handling situations characterized by an abundance of zeros in the response variable, making them highly valuable in fields such as insurance claims analysis, healthcare data analytics, and ecological studies.
In this analysis, we will explore the relationship between the response variable NbClaim and the explanatory variables Young, Male, DistLimit and GeoRegion. This modeling framework aligns with the principles outlined by Agresti (2013), a prominent figure in statistical methodology, who emphasizes the significance of considering multiple explanatory factors in regression analysis.
To model the frequency of insurance claims, we employ a Zero-Inflated Negative Binomial (ZINB) Regression approach for the response variable NbClaim, which represents the count of insurance claims and is assumed to follow a Negative Binomial distribution:
where is the mean rate of claims and is the dispersion parameter that controls the variance of the distribution. The ZINB approach allows for flexible, nonlinear relationships and accounts for excess zeros in the data. More precisely, we express the natural logarithm of as a combination of predictor variables and an additional term accounting for exposure:
where Young is a variable indicating if the driver is young, Male is a variable indicating if the driver is male, DistLimit represents the distance limit on the insurance policy, GeoRegion denotes the density of the geographical region, adjusts for the exposure variable and are the coefficients to be estimated.
Additionally, the zero-inflation component models the probability of excess zeros using a logistic regression: where represents the matrices of covariates for the or the zero-inflation model and are the vectors of coefficients.
In this model, the intercept and the coefficients are estimated through regression to quantify their impact on the expected rate of claims. The logistic regression for zero inflation allows the model to capture complex, nonlinear relationships and the presence of excess zeros in the data, providing a more flexible and accurate fit.
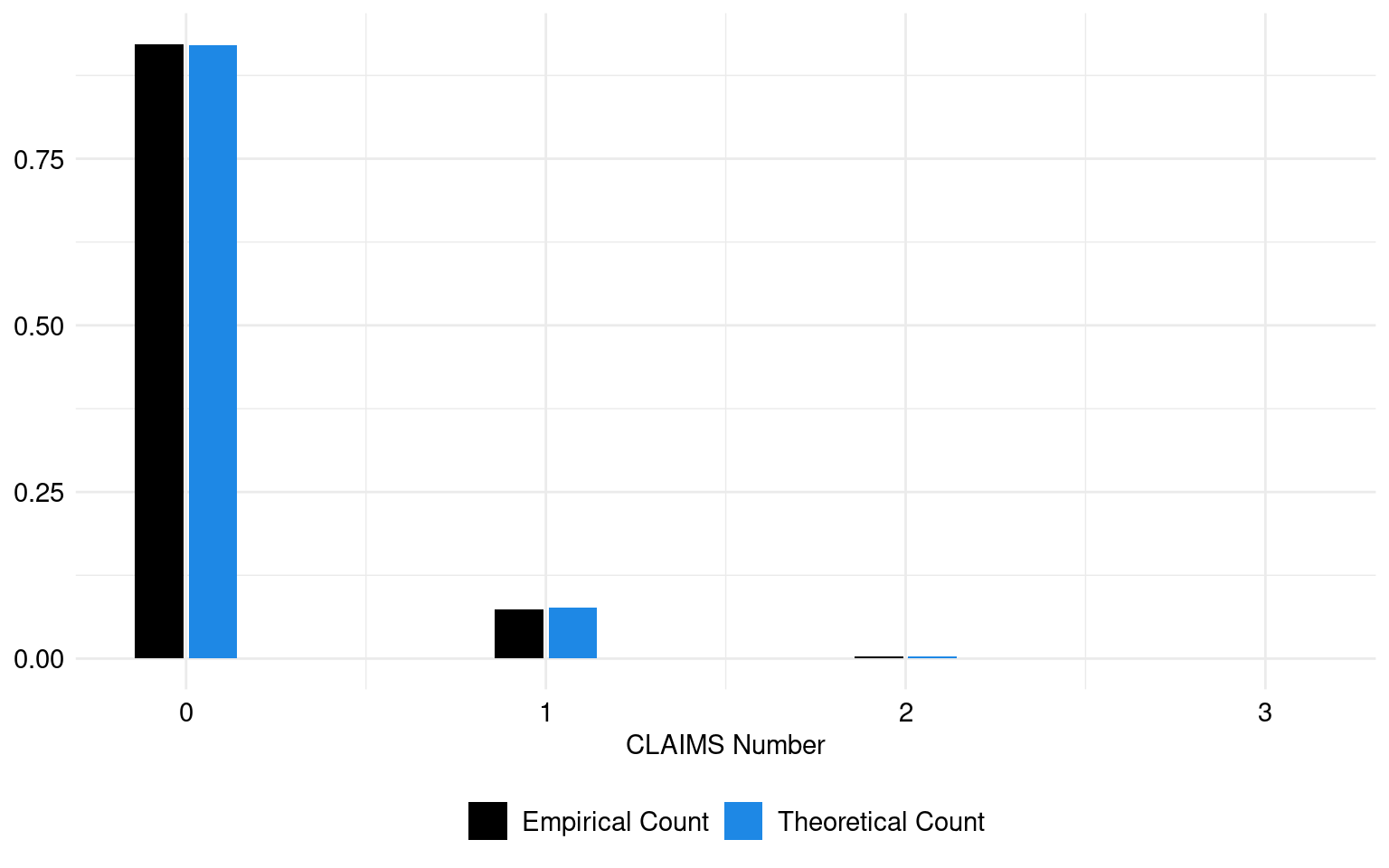
The theoretical and empirical histograms associated with a Poisson distribution are shown in Figure 1.
This Zero-Inflated Negative Binomial (ZINB) regression model is used to predict the number of claims (NbClaim) based on the predictors Young, Male, DistLimit, and GeoRegion.
Count Model (Negative Binomial with Log Link)
In the count component, the coefficients reflect the estimated change in the log count of claims associated with each predictor, relative to a reference level. Most of these coefficients are statistically significant (p < 0.05), highlighting their importance in predicting claim counts. For instance, being classified as Young (under 26 years old) or Male influences the expected number of claims.
Zero-Inflation Model (Binomial with Logit Link)
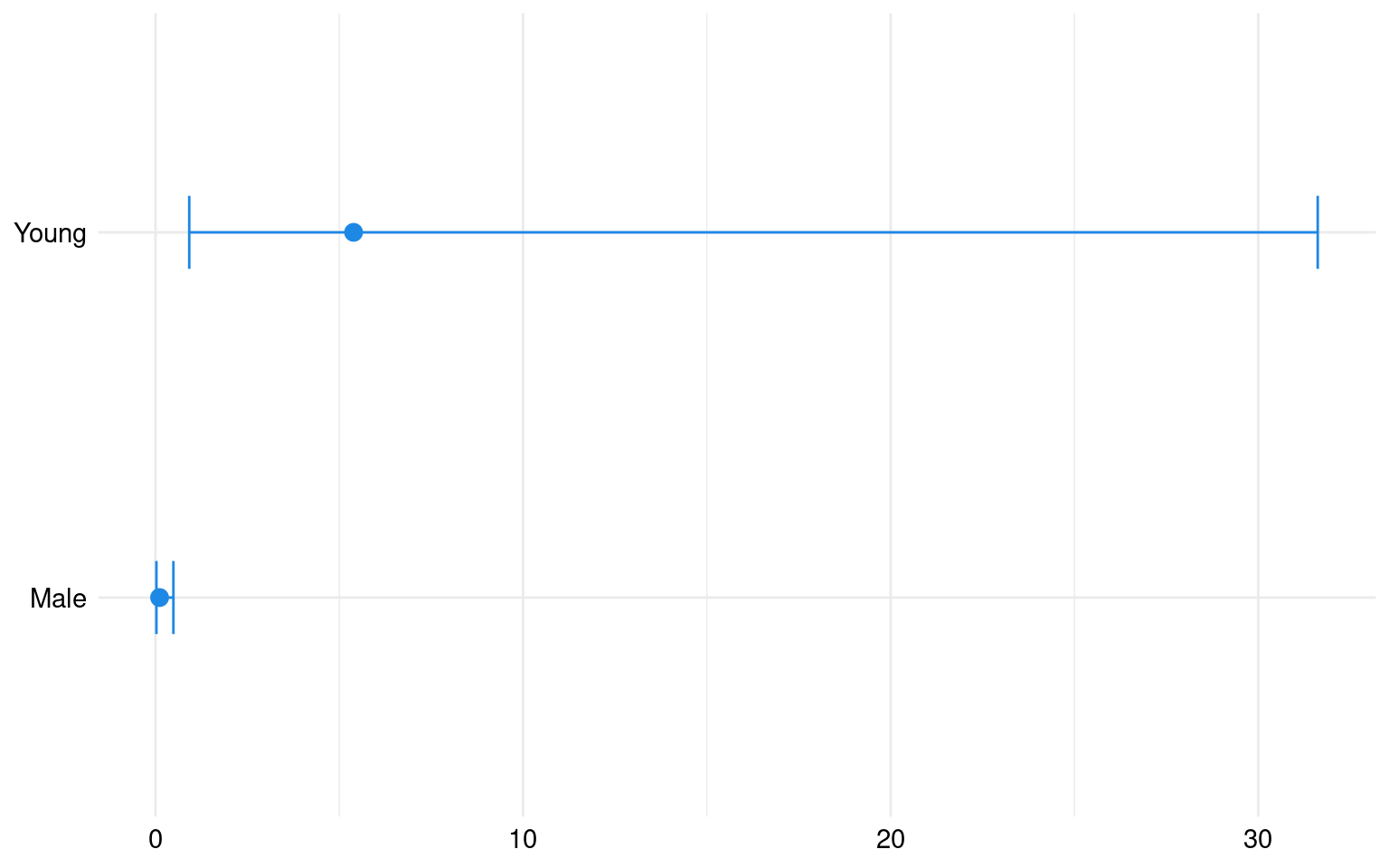
The zero-inflation model coefficients represent the log-odds of excess zeros (instances with no claims) compared to non-excess zeros. Some variables, such as Young and Male, have statistically significant coefficients (p < 0.05), indicating their influence on the likelihood of excess zeros. Specifically:
If the insured individual is classified as Young (under 26 years old), the log-odds of excess zeros increase by 1.68, suggesting that younger policyholders are more likely to contribute to the excess zeros.
Conversely, being Male reduces the log-odds of zero-inflation by 2.19, implying that male drivers are less likely to have zero claims.
The impact of DistLimit on zero-inflation varies, though most effects are not statistically significant, indicating a limited role in predicting excess zeros. Similarly, GeoRegion shows a non-significant impact, suggesting that the geographical density of the region does not strongly influence the probability of zero claims.