To model the frequency of insurance claims, we utilize a Zero-Inflated Negative Binomial (ZINB) Regression approach for the response variable ClaimNbResp, which represents the count of insurance claims and is typically assumed to follow a Poisson distribution:
where represents the mean rate of claims. The ZINB approach is particularly well-suited for handling overdispersed data with excess zeros, offering a flexible, nonlinear modeling framework. Specifically, we express the natural logarithm of as a linear combination of predictor variables, along with an adjustment for exposure:
where DrivAge denotes the driver’s age, Gender is a binary variable indicating the driver’s gender, LicAge represents the age of the driving license, BonusMalus captures the driver’s bonus-malus score, VehUsage reflects the type of vehicle usage, and adjusts for the exposure variable. The coefficients are parameters to be estimated through the regression process.
In addition to the count component, the zero-inflation part of the model accounts for the probability of excess zeros via a logistic regression model:
where represents the matrix of covariates for the zero-inflation model, and is the vector of coefficients associated with these covariates.
In this framework, the intercept and the coefficients are estimated to quantify their effects on the expected rate of claims. The logistic regression component for zero inflation enhances the model’s capacity to capture complex, nonlinear relationships and the presence of excess zeros in the data, resulting in a more flexible and accurate model fit.
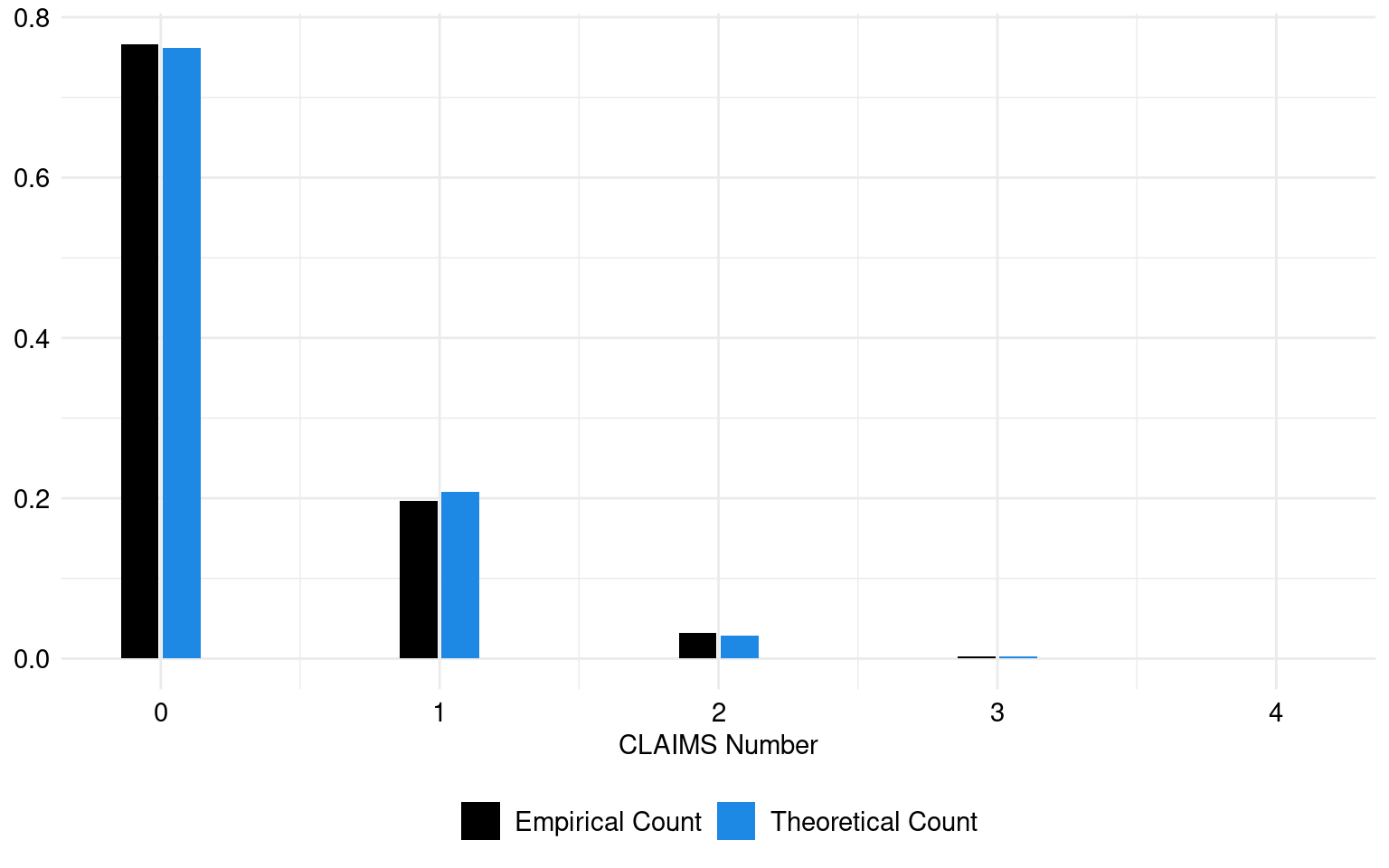
The theoretical and empirical histograms associated with a Poisson distribution are shown in Figure 1.
This Zero-Inflated regression model is used to predict NbClaim (number of claims) with DrivAge,LicAge , Gender, MariStat (marital status), BonusMalus, and VehUsage as predictor variables.
Count Model (Poisson with Log Link):
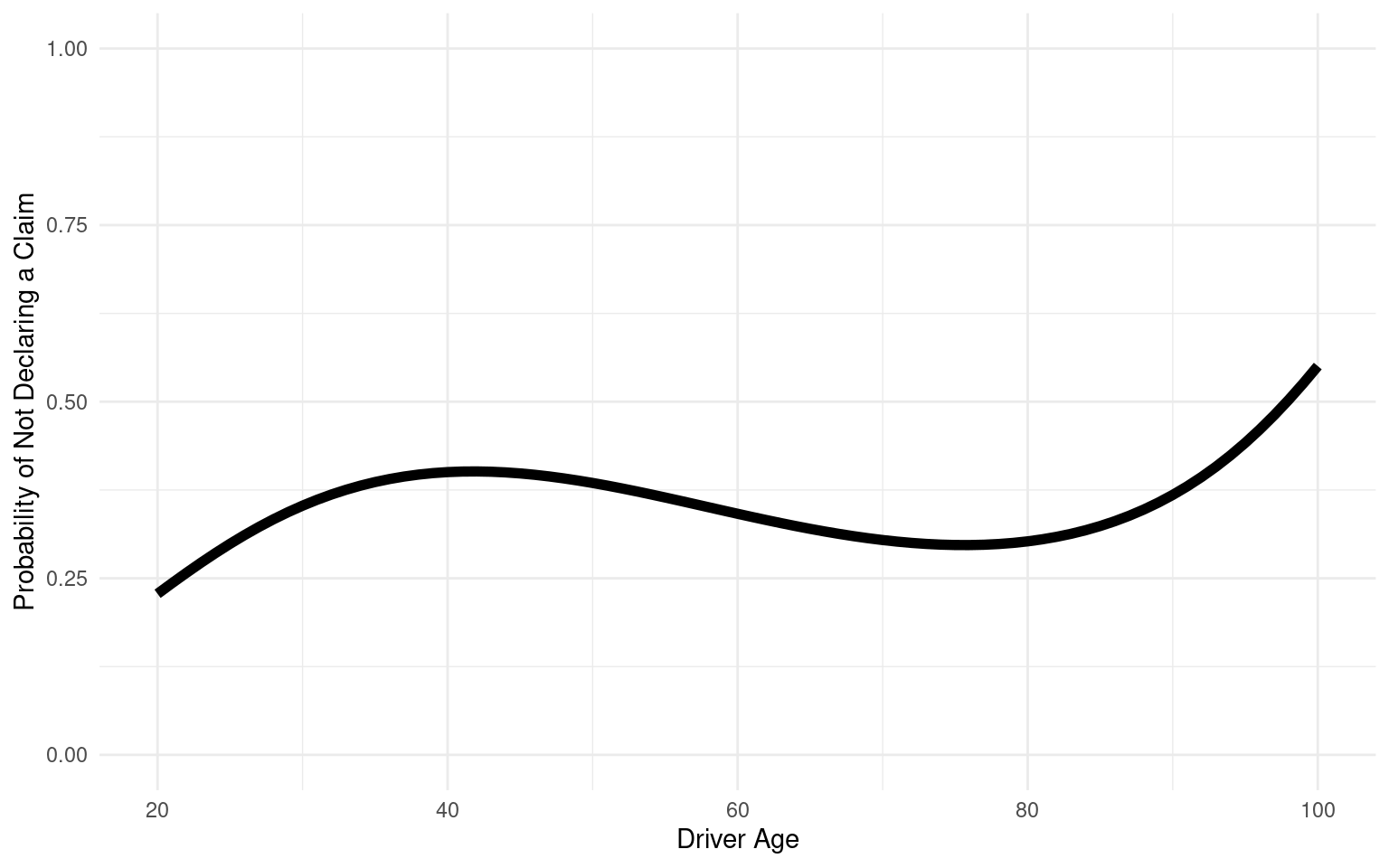
In the count component of the model, the coefficients represent the estimated change in the log count of responsible claims (ClaimNbResp) associated with each predictor level, relative to a reference level. For instance, the coefficients for drivers aged 25-40, 40-60, 50-70, and 70+ are all negative compared to the reference group (drivers younger than 25), indicating that older drivers are associated with a lower log count of responsible claims. The statistical significance of these coefficients (p < 0.05) underscores their importance in predicting the frequency of responsible claims, suggesting that age is a key factor in claim occurrence.
Zero-Inflation Model (Binomial with Logit Link):
The coefficients in the zero-inflation component model the log-odds of observing excess zeros (zero-inflation) versus non-excess zeros. The results indicate that older age groups (25-40, 40-60, 50-70, 70+) significantly reduce the log-odds of zero-inflation compared to the reference group (drivers younger than 25). This implies that younger drivers are more likely to contribute to the excess zeros in the data, potentially due to not filing claims despite having a higher risk profile.
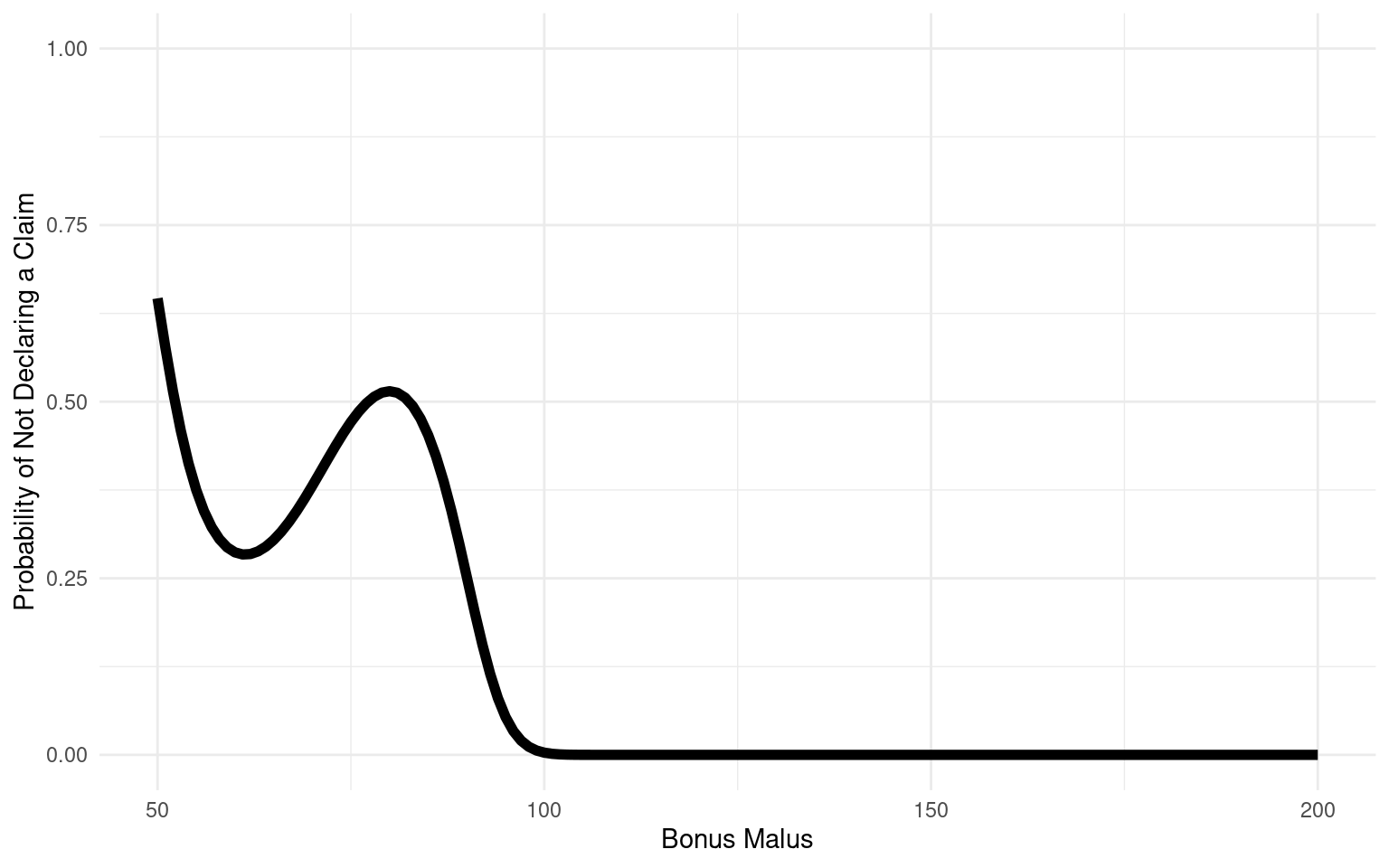
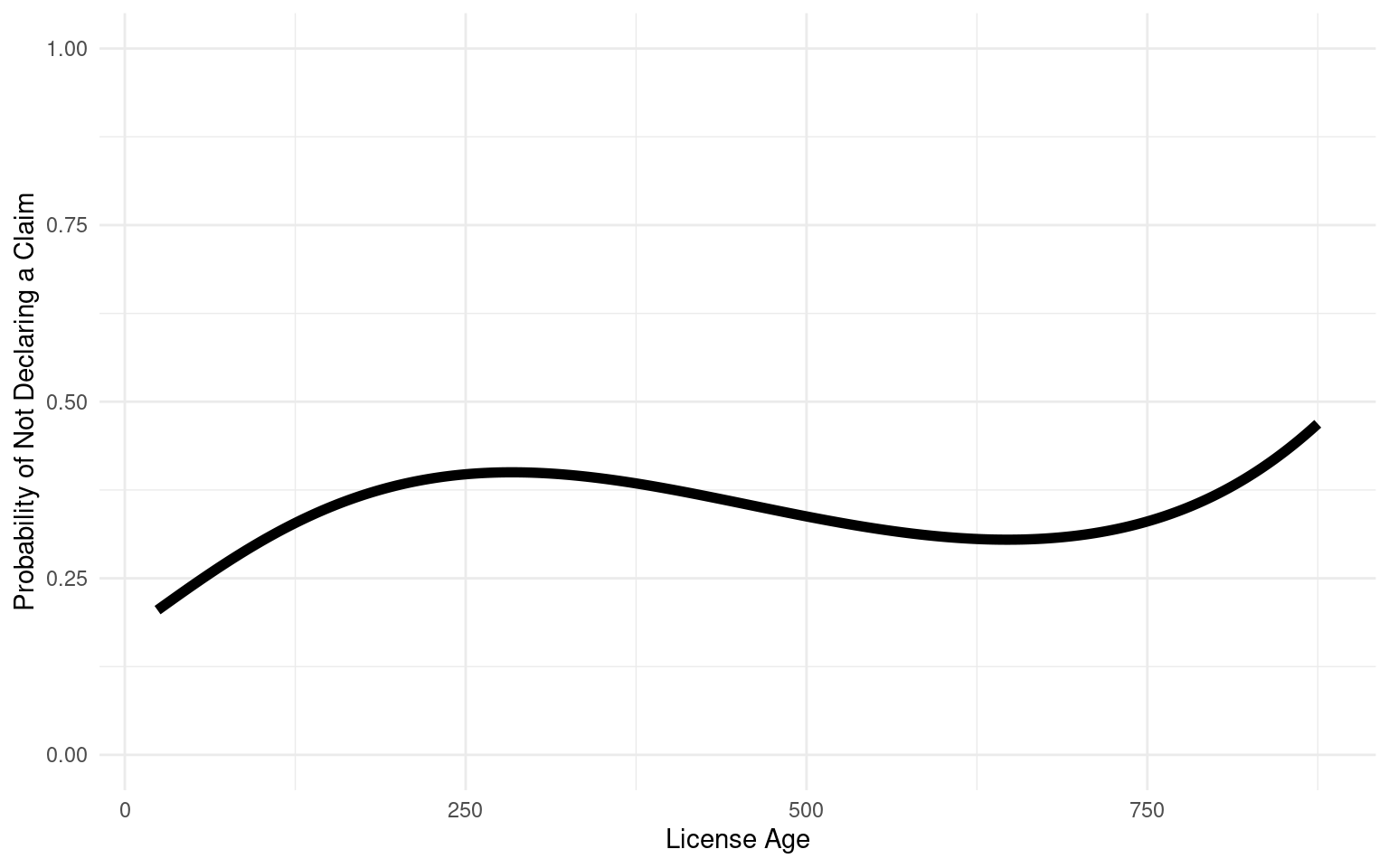
The variables LicAge and BonusMalus also influence zero-inflation, with LicAge slightly increasing the log-odds of zero-inflation, suggesting that more experienced drivers might be more likely to contribute to the excess zeros. Conversely, BonusMalus significantly decreases the log-odds, indicating that drivers with higher bonus-malus scores are less likely to contribute to the excess zeros. Interestingly, the Gender variable (Male) is not statistically significant in the zero-inflation model, suggesting that gender may not be a strong predictor of whether a claim is filed or not.
This analysis provides valuable insights into the factors that influence both the frequency of responsible claims and the likelihood of zero-inflation in the dataset, allowing for more nuanced risk assessments and pricing strategies.