Random Forest, as described in Breiman (2001), is a versatile machine learning technique that belongs to a class of ensemble learning methods. In this method, multiple decision trees are constructed during training, and their predictions are combined to produce a more accurate and stable model. Specifically, predictions are averaged for regression tasks and voted on for classification tasks.
The key idea behind Random Forest is to build a “forest” of decision trees, where each tree is trained on a random subset of the data and a random subset of the features. This randomness makes the model more robust and less prone to overfitting, which is a common issue with individual decision trees.
The process of building a Random Forest can be summarized in the following steps:
-
Bootstrap Sampling: Multiple subsets of the original dataset are created using bootstrapping, which involves randomly selecting samples with replacement.
-
Random Feature Selection: At each node of the tree, a random subset of features is selected, and the best feature from this subset is used to split the data.
-
Tree Construction: Decision trees are constructed for each bootstrap sample, and these trees grow without pruning, resulting in very deep and complex structures.
-
Aggregation: For regression tasks, predictions from all trees are averaged. For classification tasks, the most frequent prediction (mode) is selected.
The Random Forest model can be mathematically represented as:
where is the predicted value for the observation, is the total number of trees, and represents the prediction of the tree.
One of the key advantages of Random Forest is its ability to handle large datasets with high dimensionality and missing data. The random selection of features at each split ensures that the model doesn’t rely too heavily on any single feature, reducing the risk of overfitting. Additionally, Random Forest provides a measure of feature importance, ranking the contribution of each feature to the model’s predictive power. This is particularly useful for understanding which features are most influential in making predictions.
In conclusion, Random Forest is widely appreciated for its high accuracy, robustness, and ease of use. It is highly effective for both regression and classification tasks and is especially valuable in situations with a large number of features or complex relationships between variables. For additional information, see Breiman (2001).
Generalized Linear Model (GLM)
A Generalized Linear Model (GLM), first formalized by (nelder1972generalized?), extends the linear model to allow for non-normal response variables. GLMs are widely used in insurance for modeling claims data, where the response variable might follow distributions such as Poisson or binomial.
GLMs consist of three main components, each playing a critical role in how the model relates the predictor variables to the response variable:
Random Component: This specifies the probability distribution of the response variable. In GLMs, the response variable is not assumed to be normally distributed, as it is in linear regression. Instead, the response can follow a variety of distributions from the exponential family, such as Poisson, binomial, or gamma. The choice of distribution depends on the nature of the outcome (e.g., count data, binary outcomes).
Systematic Component: This represents the linear predictor, which is a linear combination of the explanatory variables (predictors). Formally, it is expressed as:
where is a vector of the explanatory variables for observation , and is a vector of coefficients. The linear predictor is the part of the model that combines the covariates to explain the variation in the response variable. This is similar to how a linear regression model operates but in the GLM, the connection between the linear predictor and the response is mediated by the link function.
-
Link Function: The link function provides the bridge between the linear predictor and the mean of the response variable, . It transforms the expected value of the response so that it can be modeled as a linear function of the predictors. The choice of link function depends on the distribution of the response. For example, a log link function is commonly used for count data (e.g., Poisson regression), and a logit link function is often used for binary outcomes (e.g., logistic regression).
The GLM model can be expressed as:
where is the link function, is the linear predictor, and is the expected outcome for observation .
Extended Calibration Error (ECE)
Extended Calibration Error (ECE) is a metric used to evaluate the calibration of probabilistic predictions, especially in the context of insurance claims modeling. It quantifies the discrepancy between predicted probabilities and observed outcomes, providing insights into the reliability of a predictive model. ECE is particularly useful for assessing models that output probabilities, as it highlights potential biases in the predicted probabilities.
-
Definition: ECE is defined as the weighted average of the absolute differences between predicted probabilities and observed frequencies of events. Formally, it is expressed as:
where is the number of bins, is the number of observations in bin , is the average predicted probability in bin , is the observed frequency of events in bin , and is the total number of observations.
Interpretation: ECE ranged provides from 0 to 1, it is a summary of how well predicted probabilities match the actual observed outcomes across different probability ranges. An ECE of zero signifies perfect calibration.
Brier Score
The Brier Score is a well-known metric for assessing the accuracy of probabilistic predictions. It is particularly useful in the insurance domain for evaluating the predictive performance of models that output probabilities of events, such as claim occurrences.
-
Definition: The Brier Score is defined as the mean squared difference between predicted probabilities and the actual binary outcomes. It can be expressed mathematically as:
where is the number of observations, is the predicted probability of the event for observation , and is the actual outcome (1 if the event occurred, 0 otherwise).
Interpretation: The Brier score ranges from 0 to 1 it measures the mean squared difference between predicted probabilities and actual outcomes. A lower Brier score indicates better calibration.
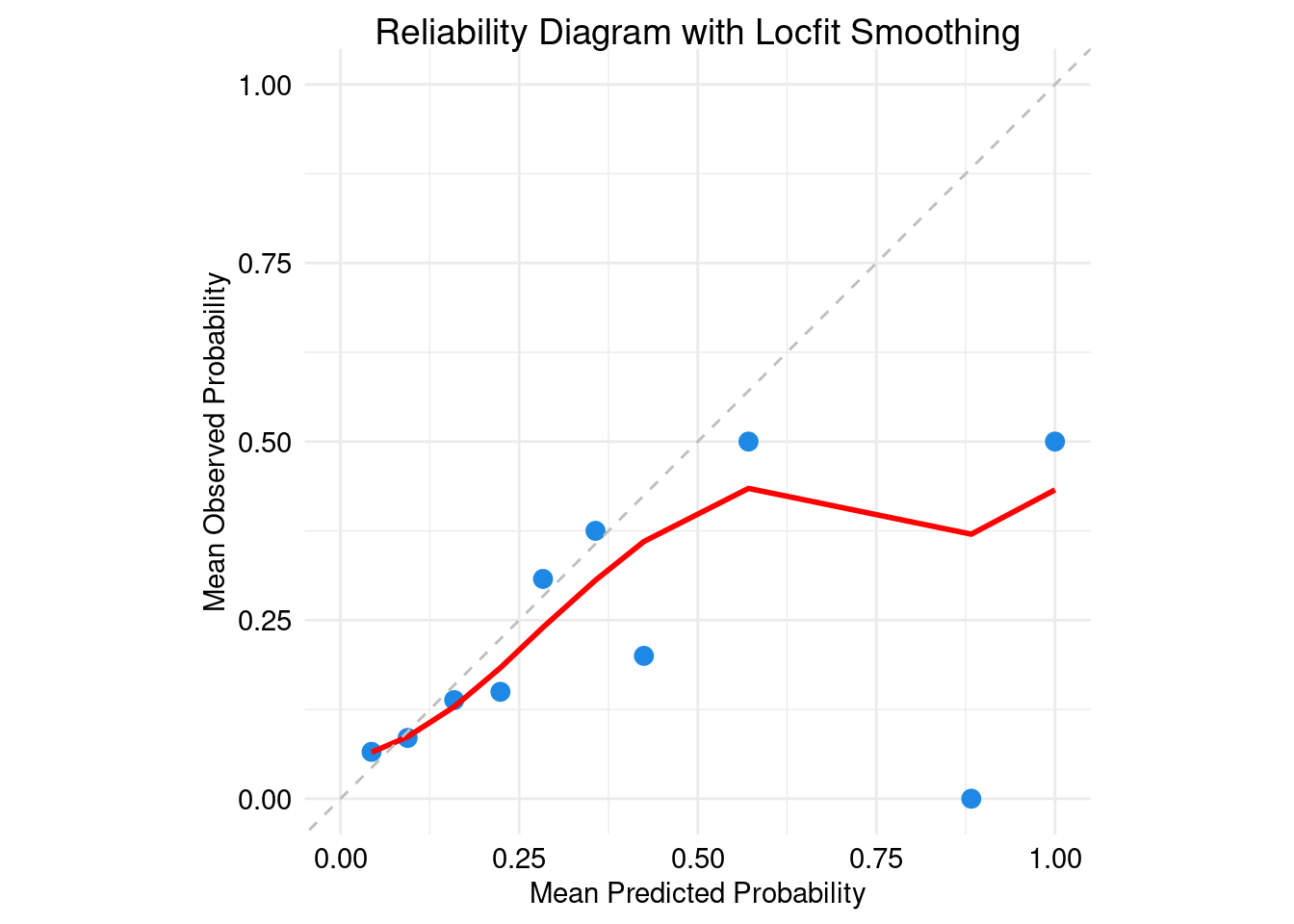
Reliability Diagram with Locfit Smoothing
The Reliability Diagram is a graphical representation used to assess the calibration of probabilistic predictions visually. It plots the predicted probabilities against the observed frequencies of events, providing insights into how well the model calibrates its probability outputs.
Construction: To construct a Reliability Diagram, predicted probabilities are binned, and the average predicted probability and observed frequency are calculated for each bin. This is typically plotted as a scatter plot of predicted probabilities versus observed proportions.
-
Locfit Smoothing: To enhance the visual interpretation of the Reliability Diagram, Locfit smoothing can be applied. Locfit is a local regression method that fits a smooth curve to the binned data, making it easier to identify trends and deviations from perfect calibration (the 45-degree line).
where are the weights based on the distances of the observations to the target bin, and represents the observed outcomes.
Interpretation: In the Reliability Diagram, points lying on the diagonal line indicate perfect calibration. Deviations above this line suggest overconfidence (predicted probabilities are too high), while points below indicate underconfidence (predicted probabilities are too low). The Locfit curve can help to visualize the overall calibration trend and highlight areas needing improvement.