In the domain of public liability for automobile accidents, particularly with a focus on elderly drivers, Generalized Additive Models (GAM) are a reliable tool for understanding and predicting accident frequencies, repair costs, and claim patterns.
By employing GAM, insurers can better anticipate future challenges, refine pricing strategies, and enhance their resilience in an ever-evolving risk environment, specifically addressing the unique risks associated with elderly drivers.
In this analysis, we explore the relationship between the response variable target and the explanatory variables DriverAge and vehicle_age. This modeling framework aligns with the principles outlined by Agresti (2013), a prominent figure in statistical methodology, who emphasizes the importance of considering multiple explanatory factors in regression analysis.
To model the frequency of insurance claims, we employ a Generalized Additive Model (GAM) approach for the response variable ClaimNB, which represents the count of insurance claims and is assumed to follow a Quasi-Poisson distribution:
where is the mean rate of claims. The GAM approach allows for flexible, nonlinear relationships between and the predictor variables through the use of smooth functions. Specifically, we express the natural logarithm of as a combination of these smooth functions and an additional term accounting for exposure:
where , are smooth functions of the predictor variables.
In this model, DriverAge represents the age of the insured individual, vehicle_age denotes the age of the vehicle, and adjusts for the exposure variable. The intercept and the smooth functions and are estimated through regression to quantify their impact on the expected rate of claims. The smooth functions allow the model to capture complex, nonlinear relationships between the predictors and the response variable, providing a more flexible and accurate fit to the data.
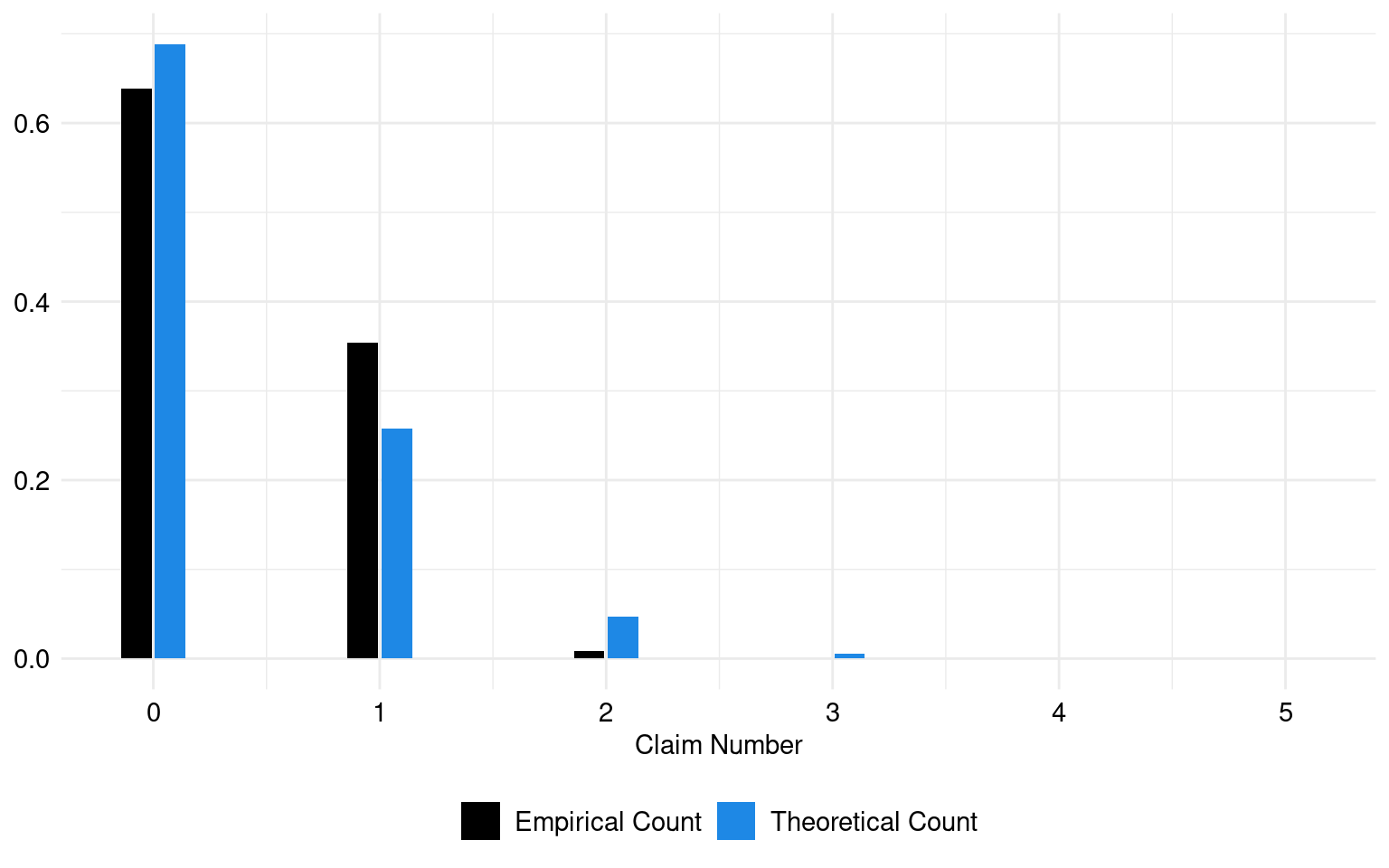
The estimated lambda parameter, which represents the mean of claims, is 0.37.
The theoretical and empirical histograms associated with a Poisson distribution are shown in Figure 1.
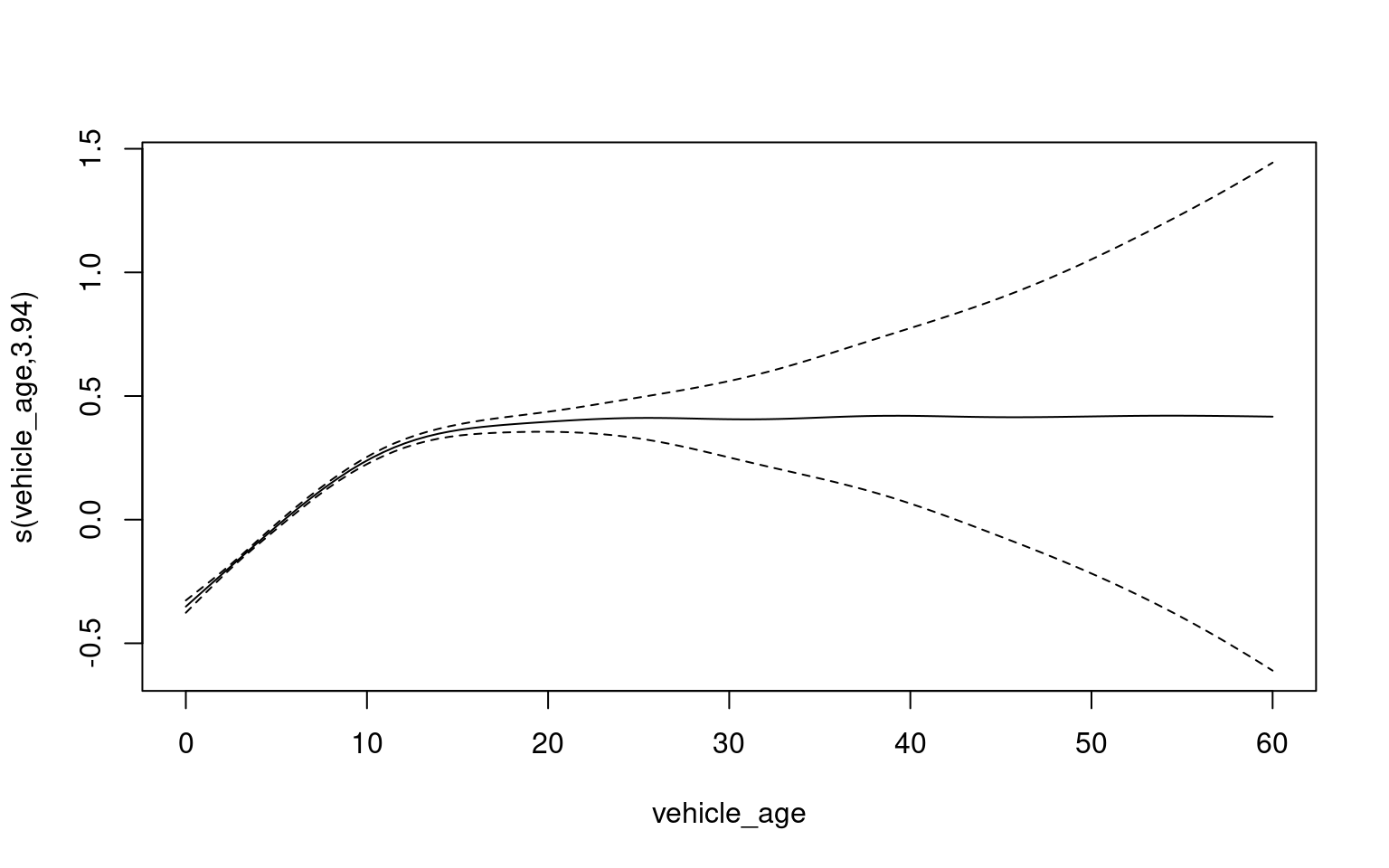
This generalized additive model (GAM) predicts the number of claims based on insured_age and vehicle_age as predictors. The smooth terms in the model are statistically significant, indicating that both insured_age and vehicle_age have a meaningful effect on the number of claims.
A positive coefficient for s(insured_age) suggests that increasing the age of the insured is associated with a higher expected log count of total liability claims. Similarly, the positive coefficient for s(vehicle_age) indicates that an increase in vehicle age is linked to a higher expected log count of claims.